

A Very Simple Example of Fine-Tuning an LLM

Normally when you fine-tune an LLM you end up making Jeff Bezos just a little bit richer due to the enormous compute power required even for the simplest of fine-tuning. I tried every free avenue I could think of to demonstrate fine-tuning using Mistral-7B-Instruct, but it failed on Google Colab free GPU and it ate up all the available resources on my machine until the process crashed.
If you're curious about the kinds of use-cases where fine-tuning is appropriate, check out my post "Why Would You Ever Fine-Tune an LLM".
Since I want you to be able to follow along on your own (which I believe always delivers the best learning), we're going to use a tiny model for our demonstration: GPT-2. We're also going to use a tiny data set (which we pushed to Hugging Face in this post). What you're about to see will be totally and completely underwhelming from a demonstration standpoint.

But I hope that by stripping everything down, it will give you a better chance to look at the details and grasp what is going on.

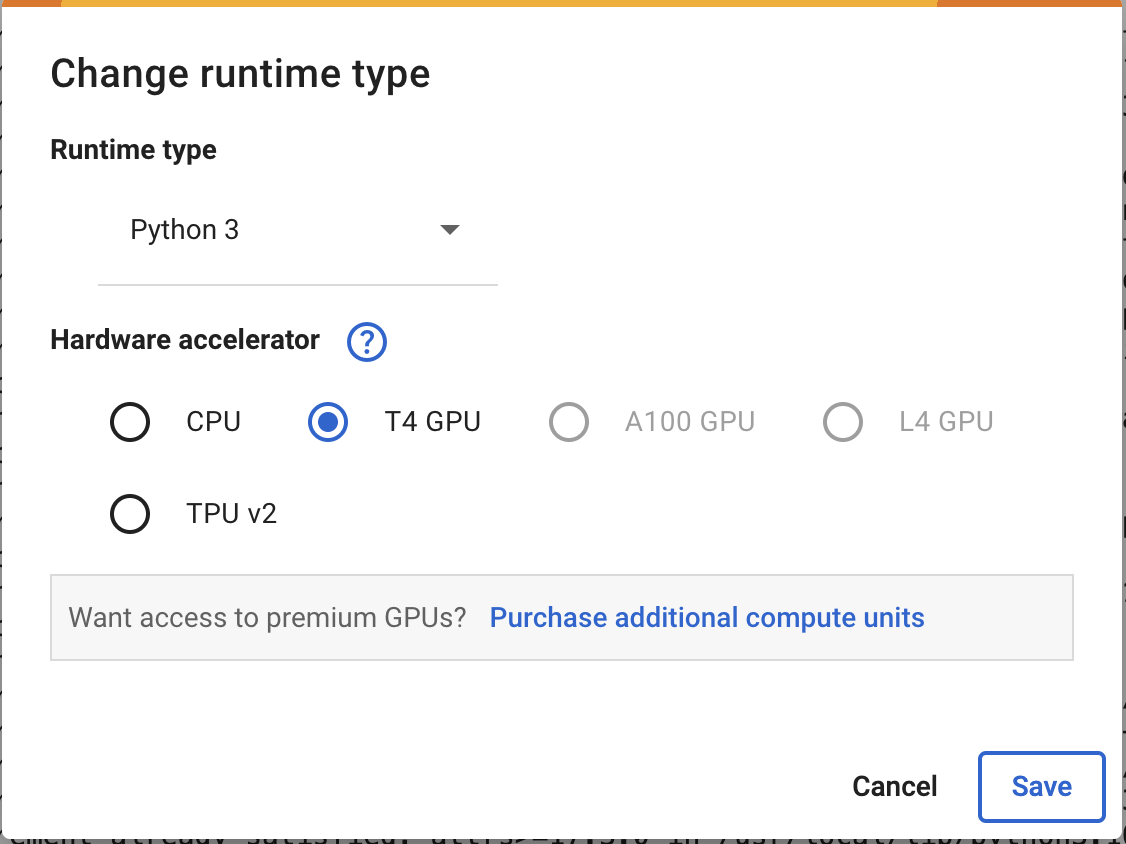
Fine-tuning, even in this stripped-down mode is still resource intensive. The first thing you should do in your Google Colab notebook is switch to the free GPU-enabled runtime.
Then choose "T4 GPU" and select "Save".
We'll start with setting things up.
!pip install transformers datasets
from transformers import GPT2Tokenizer, GPT2LMHeadModel, Trainer, TrainingArguments
from datasets import load_dataset
import torch
import json
Think of an LLM like a software service in which you have to match the API surface correctly to get a result. The surface of each LLM is as different from the next as Neptune is to Mars. So we're going to need to first transform the dataset into a format that can be understood by our target LLM. In this case, GPT-2 is very specific. It needs a big blob of text (many models you'll work with will take a series of prompts and responses instead).
original_dataset = load_dataset("samdotme/vader-speak")
# this function is used to output the right format for each row in the dataset
def create_text_row(instruction, output):
text_row = f"""Question: {instruction}. Answer: {output}"""
return text_row
# iterate over all the rows and store the final format as a giant text file
def save_file(output_file_path):
with open(output_file_path, "w") as output_file:
for item in original_dataset["train"]:
output_file.write(create_text_row(item["prompt"], item["response"]) + "\n")
# Provide the path where we want to save the formatted dataset
save_file("./training_dataset.txt")
# We now load the formatted dataset from the text file
dataset = load_dataset('text', data_files={'train': 'training_dataset.txt'})
Next, we have to manually tokenize everything. Tokenization is the process in which we convert the words and characters themselves into a numerical representation that allows the LLM to make connections between words and context. In order to fine-tune a specific LLM, you have to convert the text that you'll be using for training into the exact token representation the model understands. Each model has its own dictionary of text to token mapping, which means that you have to use the correct tokenizer or the LLM you're trying to train will have no idea what the text you've inputted means.
# Load the GPT-2 tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# Important for GPT-2 to get correct results.
tokenizer.pad_token = tokenizer.eos_token
# Worth uncommenting for understanding of the dataset structure.
# print(dataset['train']['text'])
# Tokenize the data
def tokenize_function(examples):
tokenized_inputs = tokenizer(examples['text'], truncation=True, padding=True)
tokenized_inputs["labels"] = tokenized_inputs["input_ids"].copy()
return tokenized_inputs
tokenized_datasets = dataset.map(tokenize_function, batched=True)
Now it's time to load the GPT-2 model itself.
# Load the GPT-2 model
model = GPT2LMHeadModel.from_pretrained('gpt2')
Once we have the model object loaded, we need to create a trainer object and pass some training arguments into it. In the interest of staying focused, I'm not going to delve into each of these arguments, they will become important when you train a huge model and have lots of data.
# Set up training arguments
training_args = TrainingArguments(
output_dir="./results",
overwrite_output_dir=True,
num_train_epochs=3,
per_device_train_batch_size=4,
save_steps=10_000,
save_total_limit=2,
logging_dir='./logs',
logging_steps=200,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets['train'],
)
So we've now got data, a model and a trainer. All that's left is to initiate the training.
# Train the model
trainer.train()
This part will go relatively quickly with our small model and amount of data, but this is where the time can really stack up if you're fine-tuning a bigger model and/or have more substantial data.
Once the model is fine-tuned, we save our new custom model to the local filesystem. We could also push the result to Hugging Face.
# Save the model
trainer.save_model("./vader_gpt2")
Let's Test It Out
So... what happened? Did it work?
The answer to that lies inside the newly trained model. To find out, we need to load the model and give it a prompt.
First, we load the new custom model (remember we saved it to our local filesystem). We also grab the tokenizer again.
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# Load the fine-tuned model
model = GPT2LMHeadModel.from_pretrained('./vader_gpt2')
# Load the tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
Now we try out a prompt:
# We house the LLM query logic in a function so we can call it easily later.
def take_prompt_output_response(prompt):
# Tokenize the input prompt
input_ids = tokenizer.encode(prompt, return_tensors='pt')
# Create attention mask (1 for real tokens, 0 for padding tokens)
attention_mask = torch.ones(input_ids.shape, dtype=torch.long)
# Generate text
output = model.generate(
input_ids,
attention_mask=attention_mask,
max_length=100, # Adjust the max length to control the output length
num_return_sequences=1,
no_repeat_ngram_size=2,
top_k=50,
top_p=0.95,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id # Explicitly set pad_token_id to eos_token_id
)
# Decode and print the generated text
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
# Call the model with the prompt
take_prompt_output_response("Did you remember to buy your ventilator filters?")
I get a result that shows that the training samples indeed had an effect.
Did you remember to buy your ventilator filters?. Answer: [kkshhhh] The dark side has been completely absorbed into the void [hhhkppffffhhh]. No filters needed [ppfffhhh]."
It's not really clever, but it at least mimics the training data. You can get much wittier responses if you were to use a bigger model such as Mistral-7B.
Of course, all of the above could have also been achieved with few-shot learning (see my post on few-shot learning), but I hope you can begin to see now that with fine-tuning, we are no longer prompt engineering, we are actually changing the model itself.
What Was the Extent of the Training?
To wrap up, let's examine how much of the model was retrained by the fine-tuning. We saw that if you ask it a question in the format of the training data, it responds with the classic Darth Vader breathing noises, etc. What happens if the prompt doesn't follow the format of the training data?
take_prompt_output_response("The earth is filled with wonder")
I get back the following: The earth is filled with wonder, and we are the ones who call it home."
You can see that our training data only affected the model's output when the prompt input matched the training data. It didn't affect the rest of the model in a noticeable way. This shows the special place that fine-tuning holds. It allows us to train pre-existing models in a certain area without destroying their general knowledge capabilities.



