

Why Would You Ever Fine-tune an LLM?
You can get pretty good results with few-shot prompt templates, why would you go to the trouble of spending expensive GPU hours to fine-tune an LLM with essentially the same process as few-shot prompt templates?
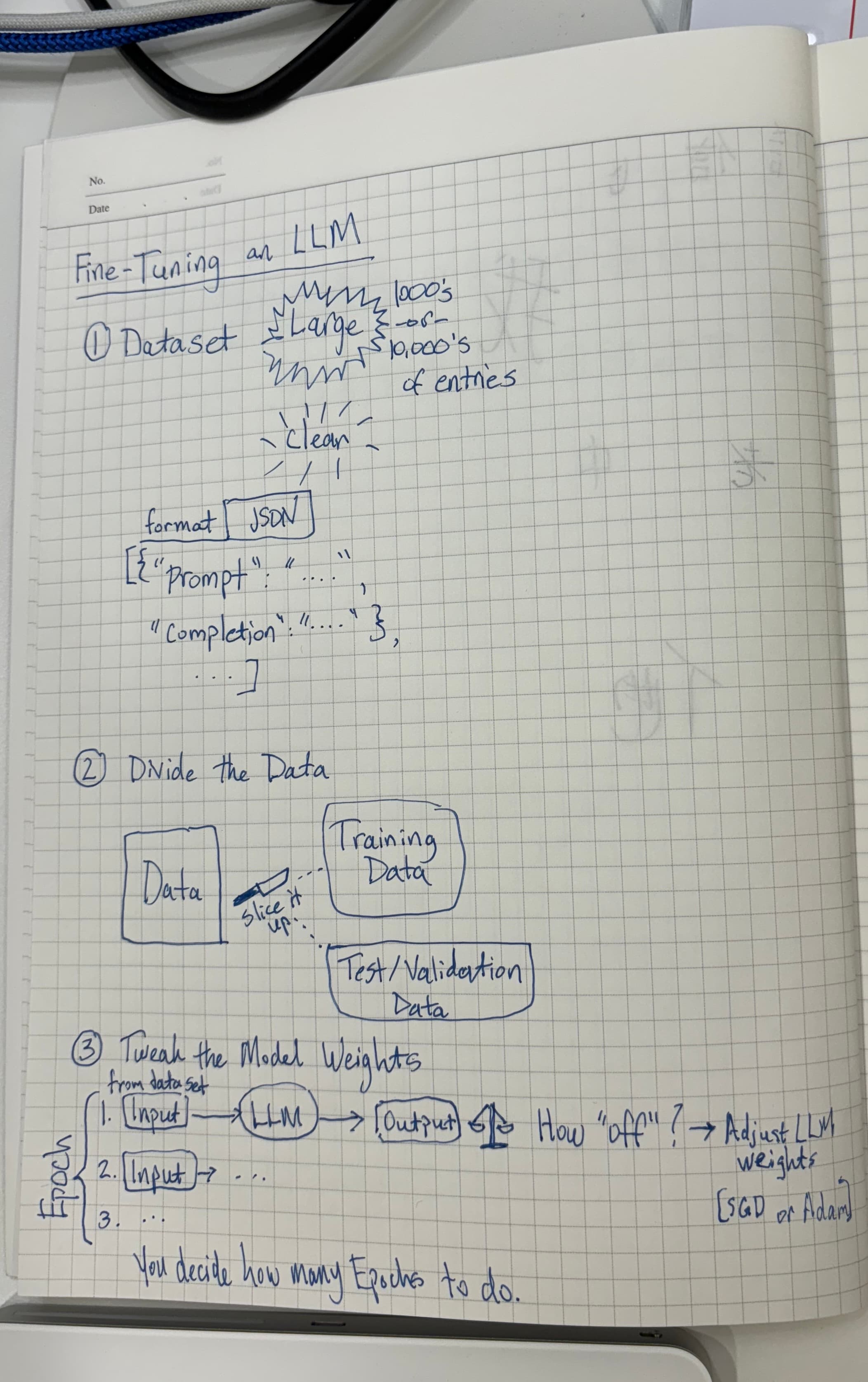
It basically comes down to data. How much do you have?

If all the data you have available is what you can personally type yourself, you probably don't have enough data to do fine-tuning on your LLM. In this case, you will get the best results with few-shot prompt templates.
On the other hand, if you can come up with 1000s of example prompt/response pairings, then fine-tuning will allow you to "bake" all of that knowledge into your LLM so that all of it can be taken advantage of on every query. With few-shot and several-shot templates you can only pass a few of these examples to the LLM on each query, so if you have a wide vocabulary or lots of different types of conversation topics to cover, fine-tuning is the way to go.




